Zagadka
Lubię czasem rozwiązać sobie jakąś dobrą zagadkę. Dobra zagadka potrafi przykuć człowieka do kartki papieru lub monitora na kilkadziesiąt minut, oferując w zamian gimnastykę szarych komórek. Potrafi też dać sporo satysfakcji z dojścia do rozwiązania. Niestety, czasami w odmętach Internetu można trafić na złą zagadkę.
Ze złymi zagadkami jest ten problem, że nie od razu wiadomo, że to naprawdę złe zagadki. Są one łudząco podobne do tych dobrych, angażują człowieka i zmuszają do wytężonego myślenia. Nie chodzi bynajmniej o to, że w złych zagadkach trudno znaleźć odpowiedź. Wręcz przeciwnie. Problemem jest to, że trudno odpowiedź zweryfikować! I siedź, człowieku, i zastanawiaj się, czy aby na pewno dobrze to rozumiesz i czy fakt przytulenia się iksa do jedynki to wskazówka, że jest tu jakieś drugie dno, czy po prostu niechlujstwo twórcy zagadki.
Odpowiedź jest trudno zweryfikować ale nie jest to niemożliwe. W powyższej zagadce na samej górze jest jedna podpowiedź: "90% fail Answer" Ha! Skoro tak, to jakieś 10% wręcz przeciwnie. Zagadka pochodzi z facebooka, wystarczy teraz przeglądnąć te kilka tysięcy komentarzy pod postem, wyznaczyć statystyki i już będzie wiadomo, jakiej odpowiedzi udzieliła jedna dziesiąta populacji. Oczywiście głupio byłoby zabierać się za te komentarze osobiście, można przecież wyręczyć się maszyną.
MATLAB czyta internet
W MATLABie istnieją zaawansowane narzędzia programistyczne umożliwiające komunikację webową, jednak nie trzeba być specjalistą, by wykonać kilka podstawowych operacji przy pomocy naprawdę prostych funkcji. Funkcja webread umożliwia wczytanie kodu html strony bezpośrednio do zmiennej tekstowej w MATLABie. Ponieważ interesują nas wszystkie komentarze, które nie wyświetlają się w całości po załadowaniu strony, należy zastosować tu pewną sztuczkę i skorzystać z mobilnej wersji strony.
http://m.facebook.com/story.php?story_fbid=2086579881666278&id=100009428599268
Można teraz zobaczyć, co i w jakiej formie odczyta funkcja webread
% odczytanie danych ze strony
podstawowy_adres = 'http://m.facebook.com/story.php?story_fbid=2086579881666278&id=100009428599268';
strona = webread(podstawowy_adres);
% zapis do pliku i otwarcie w MATLABowej przeglądarce
file = fopen('strona.html', 'w');
fprintf(file, '%s', strona);
fclose(file);
open('strona.html');
Zapis do pliku jest potrzebny tylko po to, by można było się wizualnie przekonać, co trafi do MATLABa po wykonaniu procedury webread. Jak widać, pod postem znajduje się 10 ostatnich komentarzy.
W mobilnej wersji strony można wprowadzić drobną modyfikację adresu, co poskutkuje wyświetleniem się odpowiedniej porcji wcześniejszych komentarzy. Jeśli chcemy wyświetlić 10 wcześniejszych komentarzy dodajemy na końcu adresu &p=10, kolejne 10 to końcówka &p=20 itd. Wystarczy teraz skonstruować odpowiednią pętle for i można wczytywać kolejne porcje komentarzy.
podstawowy_adres = 'http://m.facebook.com/story.php?story_fbid=2086579881666278&id=100009428599268';
liczba_komentarzy = 8500;
for i = 0:10:liczba_komentarzy-10
url = [podstawowy_adres '&p=' num2str(i)];
strona = webread(url);
end
Wyrażenia regularne
Powyższa pętla oczywiście na wiele się nie zda. Podawane przez użytkowników odpowiedzi trzeba będzie dopiero wyłuskać z kodu html i tu z pomocą przychodzą wyrażenia regularne. Trzeba tylko przez chwilę zastanowić się, gdzie znajduje się to czego szukamy. Jeśli podglądniemy kod html strony to okazuje się, że nazwa komentującego użytkownika zawarta jest pomiędzy znacznikami <h3></h3>, później mamy otwarcie sekcji <div> i tam pojawia się komentarz. Najczęściej jest to postulowana odpowiedź i nic więcej. Dla uproszczenia sprawy pominę inne typy komentarzy. Tj. jeśli ktoś poza podaniem swojej odpowiedzi dołączy jakieś wyjaśnienie w formie tekstu albo rozpocznie od wstawienia obrazka czy czegokolwiek innego, jego odpowiedź nie będzie analizowana (nie jest to niemożliwe, ale byłoby bardzo trudne, jeśli ktoś ma pomysł jak się za to zabrać, niech się pochwali 🙂 )Podsumowując, należy w tekście html odszukać liczbę, która pojawia się tuż za znacznikami </h3><div> i przed jakimkolwiek kolejnym znacznikiem (czyli przed <).
Wzór będzie wyglądać tak:
wyrazenie = '(?<=</h3><div>)\d+(?=<)'; wyniki = regexp(strona, wyrazenie, 'match')
Pełne wyjaśnienie symboliki wyrażeń regularnych to materiał na kilka osobnych wpisów, nadmienię więc jedynie, że \d+ oznacza jedną lub więcej cyfr - tego właśnie poszukujemy w każdym komentarzu. Upraszczamy oczywiście bardzo, poszukując wyłącznie liczb całkowitych i ignorując całą resztę.
Zapis wyników
Poniżej cały kod umożliwiający zebranie wyników ze strony. W momencie pisania tego tekstu komentarzy pod postem jest ok 8500. Zmienna wyniki będzie więc miała właśnie taki rozmiar. Każda porcja wyników jest konwertowana do typu liczbowego - pierwotnie jest to ciąg znaków.
podstawowy_adres = 'http://m.facebook.com/story.php?story_fbid=2086579881666278&id=100009428599268';
liczba_komentarzy = 8500;
wyrazenie = '(?<=</h3><div>)\d+(?=<)';
wyniki = NaN(1, liczba_komentarzy);
for i = 0:10:liczba_komentarzy-10
url = [podstawowy_adres '&amp;p=' num2str(i)];
strona = webread(url);
porcja = regexp(strona, wyrazenie, 'match');
porcja = str2double(porcja);
n = length(porcja);
wyniki(i+1:i+n) = porcja;
end
Operacja może zająć trochę czasu.
Przetwarzanie wyników
Po zapełnieniu wektora wynikowego wartościami należy je przetworzyć. Pierwsza sprawa, to usunięcie wszystkich elementów oznaczonych jako NaN wynikających z pojawiania się komentarzy zawierających cokolwiek innego niż liczbę całkowitą.
in = isnan(wyniki); wyniki(in) = []; N = length(wyniki);
Zliczanie liczby użytkowników wskazujących na konkretną odpowiedź będzie prostsze, jeśli dokonamy konwersji wyniku do typu categorical. Funkcja histcounts zliczy nam wtedy dokładnie to, czego oczekujemy - ile jest odpowiedzi danego typu w całym wektorze wynikowym. W wynikach pojawią się oczywiście pozycję typu 123, czy 666, które możemy natychmiast wyeliminować. Możemy założyć, że odpowiedzi stanowiące mniej niż 1% nas nie interesują.
wyniki = categorical(wyniki); [N,kategorie] = histcounts(wyniki); idx = N < (0.01 * length(wyniki)); % wyszukanie najmniej popularnych odpowiedzi (poniżej 1%) N(idx) = []; kategorie(idx) = []; ax = axes; %przygotowanie wykresu bar(ax, N); ax.XTickLabel = kategorie;

Wygodnie będzie analizować wyniki jeśli zmienimy wartości na osi Y na procentowe. Można również dodać linię wyznaczającą granicę 10%.
N_p = 100 * N./length(wyniki); bar(ax, N_p); hold(ax, 'on'); plot(ax, ax.XLim, [10 10], 'red') ax.XTickLabel = kategorie;
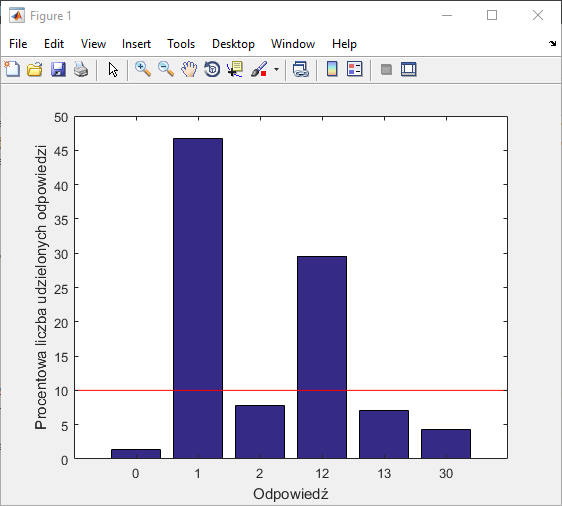
Skorzystanie z mądrości tłumu nie dało niestety jednoznacznej odpowiedzi. Jak by nie patrzeć, w pobliżu 10% lokują się dwie pozycje 🙂 Lekką przewagę ma"dwójka" i skłaniam się do uznania jej za zwycięzce (tj. za prawidłową odpowiedź) ale to moja subiektywna opinia.