Autorem wpisu jest Michał Hałoń – doktorant na Wydziale Elektroniki i Technik Informacyjnych Politechniki Warszawskiej. Zainspirowany wpisem o Wordle na blogu Loren Shure oraz polskim odpowiednikiem gry na literalnie.fun, przygotował analizę rozwiązania dla tej popularnej łamigłówki.
Od pierwszych tygodni 2022 roku ogromną popularność w sieci zdobywa przeglądarkowa gra Wordle, która polega na odgadnięciu pięcioliterowego słowa w maksymalnie sześciu próbach. W tym wpisie wykorzystamy program MATLAB do automatycznego wyszukiwania słów stanowiących potencjalne rozwiązania zagadki dla polskiej wersji gry.
Zasady opisywanej gry są bardzo proste – dla każdej litery wpisanego słowa otrzymujemy informację, czy w docelowej odpowiedzi znajduje się ona w odpowiednim miejscu (kolor zielony), w innym miejscu (kolor żółty) lub nie ma go wcale (kolor szary). Gdy wszystkie literki wyświetlą się na zielono – znaleźliśmy hasło. Ponadto, danego dnia wszyscy użytkownicy próbują odgadnąć to samo słowo.
Strategii na dobór odpowiednich wyrazów wpisywanych w grze, szczególnie na samym początku jest wiele - można kierować się intuicją, naszymi ulubionymi słowami czy takimi, jakie najczęściej wykorzystujemy. Można także podejść do zagadnienia od strony matematycznej i spróbować użyć wyrazów, których litery jednocześnie nie powtarzają się i często występują w zbiorze słów, które mogą stanowić szukane hasło.
Wykorzystanie tej metody może zwiększyć nasze szanse na sukces, jednak jej zrealizowanie wymaga dostępu do odpowiednich danych oraz oprogramowania. Na szczęście, taka analiza została już przeprowadzona i opisana na blogu Loren on the Art of MATLAB – udostępniony skrypt napisany w programie MATLAB, w zdecydowanej większości przypadków odgaduje poszukiwane słowo w ramach sześciu dostępnych prób.
W tym wpisie wykorzystam wspomniany wyżej (a miejscami przeze mnie zmodyfikowany) skrypt do przeprowadzenia analogicznych rozważań dla polskiej wersji gry Wordle, która jest dostępna między innymi na stronie literalnie.fun.
W zasadzie jedyną różnicą pomiędzy oryginalną grą Wordle, a analizowaną przeze mnie wersją jest język – zachodzi zatem konieczność wykorzystania zbioru wszystkich pięcioliterowych słów w języku polskim. Taki zbiór możemy uzyskać poprzez pobranie oraz odpowiednie zmodyfikowanie listy słów do gier według zasad dopuszczalności SJP.PL.
% read the list of words into a string array
r = readlines('slowa.txt');
% Wordle uses all upper case letters
r = upper(r);
% get the list of unique five letter words
word5 = unique(r(strlength(r)==5));
% display number of words in arrays
fprintf("Lista zwiera %i słów pięcioliterowych spośród %i wszystkich słów.\n", height(word5), height(r))
W ten sposób, spośród ponad trzech milionów wszystkich słów, uzyskaliśmy listę 28 535 tych pięcioliterowych, których użyjemy w dalszych analizach. Warto zaznaczyć, że jest to zdecydowanie więcej niż w przypadku anglojęzycznej wersji (nieco ponad 4 500 wyrazów). Możemy dodatkowo wykreślić rozkład liczby słów w zależności od ich długości.
% create variable and array
max_words_len = 15;
words_len = nan(max_words_len,1);
% calculate word count of given length
for cur_len = 1:max_words_len
words_len(cur_len) = height(unique(r(strlength(r)==cur_len)));
end
% plot bar graph
bar(words_len)
% display numbers in desired format
ax = gca;
ax.YRuler.Exponent = 0;
% set title and labels
title('Rozkład liczby słów według ich długości');
xlabel('Liczba liter w słowie');
ylabel('Liczba słów');

Można zauważyć, że pięcioliterowe słowa stanowią niewielki podzbiór w porównaniu do pozostałych, dłuższych wyrazów, natomiast największą grupę stanowią słowa dwunastoliterowe. Wykorzystanie tak długich wyrazów w grze Wordle mogłoby stanowić nie lada wyzwanie.
Chcąc wdrożyć wspomnianą wcześniej strategię zastosowania na początku słów zawierających niepowtarzające się oraz często występujące litery, posłużymy się poniższym kodem do określenia ich liczności wśród pięcioliterowych wyrazów.
% split our words into their individual letters
letters = split(word5,"");
% this also creates leading and trailing blank strings, drop them
letters = letters(:,2:end-1);
% view the counts of letter use
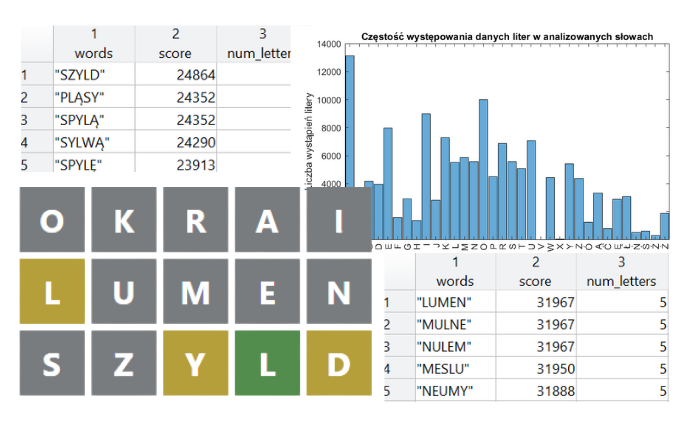
h = histogram(categorical(letters(:)));
title("Częstość występowania danych liter w analizowanych słowach")
ylabel("Liczba wystąpień litery")
% create table with letters and their scores
lt = table(h.Categories',h.Values','VariableNames',["letters","score"]);
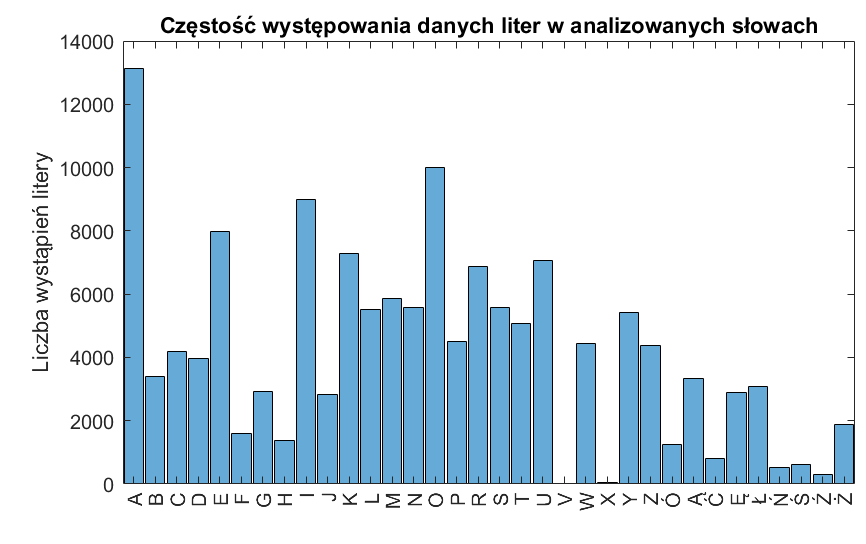
Nie powinno dziwić, że w analizowanych słowach najczęściej pojawiają się samogłoski ‘AEIOU’. Wśród ponad 28 000 słów, litera ‘A’ widnieje się ponad 13 000 razy, a litera ‘O’ prawie 10 000 razy. Na drugim końcu znajdują się litery ‘X’ i ‘V’, które wystąpiły jedynie odpowiednio 50 oraz 9 razy.
Zgodnie z artykułem na blogu Loren on the Art of MATLAB oraz intuicją, warto zatem na początku rozgrywki wybierać te słowa, które zawierają często występujące litery, co zwiększa szanse na ich oznaczenie kolorem żółtym lub zielonym, a co z kolei stanowi dla nas cenną informację. W celu odnalezienia takich słów, każdej literze przypiszemy obliczoną liczbę jej wystąpień, następnie wyniki zsumujemy dla każdego wyrazu osobno i posortujemy malejąco, dzięki czemu na samej górze takiej listy uzyskamy najbardziej dla nas wartościowe słowa.
% for each letter, replace it with its corresponding letter score letters_score = arrayfun(@(x) lt.score(lt.letters==x),letters); % sum the letter scores to create word scores word_score = sum(letters_score,2); % find the top scores and their corresponding words [top_scores,top_idx] = sort(word_score,1,"descend"); word_scores = table(word5(top_idx),top_scores,'VariableNames',["words","score"]);

Najlepszy wynik uzyskało słowo ‘KAKAA’, które składa się aż z trzech najczęściej występujących liter ‘A’ oraz dwóch liter ‘K’, które stanowią najczęściej występujące spółgłoski. W pozostałych propozycjach również często występuje litera ‘A’. Do uzyskanych rezultatów dodajmy jeszcze pierwszy warunek – unikalności liter w wyrazie.
% find how many unique letters are in each word word_scores.num_letters = arrayfun(@(x) numel(unique(char(x))),word_scores.words); % keep only the words with no repeated letters top_words_norep = word_scores(word_scores.num_letters==5,:); head(top_words_norep)
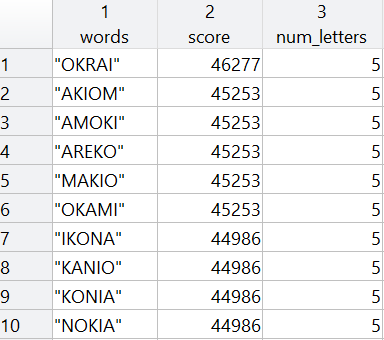
Zwycięzcą rankingu w polskiej wersji gry Wordle (według przedstawionego algorytmu) zostało słowo ‘OKRAI’, które według SJP jest dopełniaczem słowa ‘OKRAJ’ (regionalnie o brzegu, krawędzi, skraju czegoś). Zawiera trzy najczęściej występujące samogłoski (‘AOI’) oraz dwie najczęściej występujące spółgłoski (‘KR’). Kolejne pięć wyrazów uzyskało identyczny wynik, z czego wszystkie poza ‘AREKO’ stanowią anagramy, podobnie w przypadku czterech kolejnych słów.
Poza słowami ‘IKONA’ oraz ‘NOKIA’, zaprezentowane powyżej wyrazy z TOP 10 to słowa mało znane i rzadko stosowane na co dzień. Zaufajmy jednak algorytmowi i wpiszmy pierwszy zaproponowany wyraz w grze literalnie.fun:

Wszystkie litery zostały oznaczone kolorem szarym, co oznacza brak ich występowania w szukanym słowie. Informację zwrotną na temat kolorowych oznaczeń przekazujemy do MATLABa w wektorze results za pomocą następujących cyfr: 0 dla koloru szarego, 1 dla koloru żółtego oraz 2 dla zielonego. W tym przypadku, wektor results przyjmie postać [0,0,0,0,0]. Wykorzystując funkcję filter_words, która usuwa z listy niepasujące słowa na podstawie informacji z dotychczasowych prób, uzyskamy kolejne propozycje do wpisania. Przed wyświetleniem, lista propozycji zostanie dodatkowo posortowana według liczby unikalnych liter.
% our first guess guesses = "OKRAI"; % encode the feedback results = [0,0,0,0,0]; % filter down to the remaining candidates top_words_filtered = filter_words(word_scores,guesses,results); top_words_filtered = sortrows(top_words_filtered,'num_letters','descend'); top_words_filtered(1:5,:)

Liczba wyrazów dostępnych do wykorzystania została zredukowana z 28 535 do 3231 - prawie dziewięciokrotnie. Kolejną propozycją z największym wynikiem jest słowo ‘LUMEN’. Zobaczmy, jakie wyniki uzyskamy po wpisaniu do gry:

Tym razem pierwsza litera została oznaczona żółtym kolorem, a pozostałe na szaro. Do macierzy results dodamy zatem wiersz [1,0,0,0,0].
% our previous guesses
guesses = [guesses; "LUMEN"];
% encode the feedback
results = [results; 1,0,0,0,0];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results);
top_words_filtered = sortrows(top_words_filtered,'num_letters','descend');
try
top_words_filtered(1:5,:)
catch
top_words_filtered
end

Spośród 58 słów zaproponowanych do wykorzystania, wybieramy dalej wyraz ‘SZYLD’:
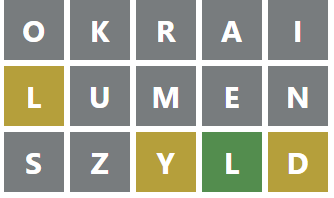
Wciąż jeszcze nie udało nam się uzyskać docelowej odpowiedzi, ale wiemy już, że czwartą literą hasła jest ‘L’.
% our previous guesses
guesses = [guesses; "SZYLD"];
% encode the feedback
results = [results; 0,0,1,2,1];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results);
top_words_filtered = sortrows(top_words_filtered,'num_letters','descend');
try
top_words_filtered(1:5,:)
catch
top_words_filtered
end

Otrzymaliśmy jedną propozycję, która powinna stanowić poszukiwane hasło. Sprawdźmy:
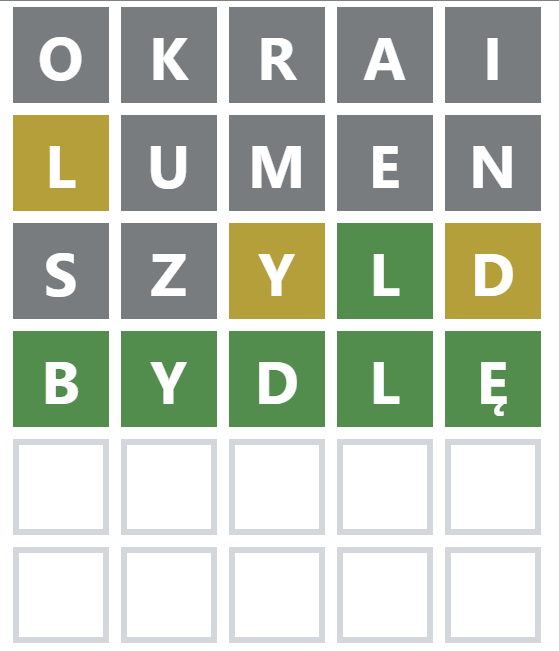
Udało się – i to już w czwartej próbie! Sprawdziliśmy zatem w praktyce, że proponowany algorytm, docelowo przygotowany do oryginalnej gry Wordle, jest w stanie odgadnąć hasło także dla jej polskiej wersji. Z racji, że każdego dnia pojawia się nowe słowo do odgadnięcia, zachęcam do dalszego testowania, czy z pomocą MATLABa uda się je odnaleźć w maksymalnie sześciu próbach.
W drugiej części ocenię skuteczność prezentowanej metody na podstawie wszystkich możliwych rozgrywek, a także dokonam próby udoskonalenia algorytmu w celu zwiększenia jego dokładności.
Poniżej znajduje się kod całego programu:
% Based on the code from the blog post:
% https://blogs.mathworks.com/loren/2022/01/18/building-a-wordle-solver/
%% LOAD DATA
% read the list of words into a string array
r = readlines('slowa.txt');
% Wordle uses all upper case letters
r = upper(r);
% get the list of unique five letter words
word5 = unique(r(strlength(r)==5));
% display number of words in arrays
fprintf("Lista zwiera %i słów pięcioliterowych spośród %i wszystkich słów.\n",height(word5),height(r))
%% GET WORDS LENGTH HISTOGRAM
% create variable and array
max_words_len = 15;
words_len = nan(max_words_len,1);
% calculate word count of given length
for cur_len = 1:max_words_len
words_len(cur_len) = height(unique(r(strlength(r)==cur_len)));
end
% plot bar graph
bar(words_len)
% display numbers in desired format
ax = gca;
ax.YRuler.Exponent = 0;
% set title and labels
title('Rozkład liczby słów według ich długości');
xlabel('Liczba liter w słowie');
ylabel('Liczba słów');
%% LETTERS FREQUENCY IN FIVE LETTER WORDS
% split our words into their individual letters
letters = split(word5,"");
% this also creates leading and trailing blank strings, drop them
letters = letters(:,2:end-1);
% view the counts of letter use
figure;
h = histogram(categorical(letters(:)));
title("Częstość występowania danych liter w analizowanych słowach")
ylabel("Liczba wystąpień litery")
% create table with letters and their scores
lt = table(h.Categories',h.Values','VariableNames',["letters","score"]);
%% CALCULATE SCORES
% for each letter, replace it with its corresponding letter score
letters_score = arrayfun(@(x) lt.score(lt.letters==x),letters);
% sum the letter scores to create word scores
word_score = sum(letters_score,2);
% find the top scores and their corresponding words
[top_scores,top_idx] = sort(word_score,1,"descend");
word_scores = table(word5(top_idx),top_scores,'VariableNames',["words","score"]);
%% ADD UNIQUE LETTERS COLUMN
% find how many unique letters are in each word
word_scores.num_letters = arrayfun(@(x) numel(unique(char(x))),word_scores.words);
% keep only the words with no repeated letters
top_words_norep = word_scores(word_scores.num_letters==5,:);
head(top_words_norep)
%% FIRST ATTEMPT
% our first guess
guesses = "OKRAI";
% encode the feedback
results = [0,0,0,0,0];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results);
top_words_filtered = sortrows(top_words_filtered,'num_letters','descend');
top_words_filtered(1:5,:)
%% NEXT ATTEMPTS
% our previous guesses
guesses = [guesses; "SZYLD"];
% encode the feedback
results = [results; 0,0,1,2,1];
% filter down to the remaining candidates
top_words_filtered = filter_words(word_scores,guesses,results);
top_words_filtered = sortrows(top_words_filtered,'num_letters','descend');
try
top_words_filtered(1:5,:)
catch
top_words_filtered(:,:)
end
%% FUNCTIONS
function word_scores_filtered = filter_words(word_scores,words_guessed,results)
% remove words_guessed since those can't be the answer
word_scores_filtered = word_scores;
word_scores_filtered(matches(word_scores_filtered.words,words_guessed),:) = [];
% filter to words that have correct letters in correct positions (green letters)
[rlp,clp] = find(results==2);
if ~isempty(rlp)
for ii = 1:numel(rlp)
letter = extract(words_guessed(rlp(ii)),clp(ii));
% keep only words that have the correct letters in the correct locations
word_scores_filtered = word_scores_filtered(extract(word_scores_filtered.words,clp(ii))==letter,:);
end
end
% filter to words that also contain correct letters in other positions (yellow letters)
[rl,cl] = find(results==1);
if ~isempty(rl)
for jj = 1:numel(rl)
letter = extract(words_guessed(rl(jj)),cl(jj));
% remove words with letter in same location
word_scores_filtered(extract(word_scores_filtered.words,cl(jj))==letter,:) = [];
% remove words that don't contain letter
word_scores_filtered(~contains(word_scores_filtered.words,letter),:) = [];
end
end
% filter to words that also contain no incorrect letters (grey letters)
[ri,ci] = find(results==0);
if ~isempty(ri)
for kk = 1:numel(ri)
letter = extract(words_guessed(ri(kk)),ci(kk));
% remove words that contain incorrect letter
word_scores_filtered(contains(word_scores_filtered.words,letter),:) = [];
end
end
end % filter_words